DDD & Testing Strategy
In my previous post I discussed the unit of unit testing. Uncle Bob happened to blog about the same subject few days after my post. In that post he proposed the following rule:
“Mock across architecturally significant boundaries, but not within those boundaries.”
In this post I’ll go through my current testing strategy of the business applications implemented using Domain Driven Design (DDD) principles and patterns. The units that I have found meaningful to test in isolation are quite close (if not exactly) what Uncle Bob suggested in his post. I hope this blog post illustrates how that high level rule can be applied in practice.
I assume that the reader is somewhat familiar with the DDD concepts like domain, entity, repository etc. I’m also expecting that test automation is not black magic to you.
DISCLAIMER: I use term mocking as a general term meaning all kind of test substitutes inluding spies, mocks, stubs and what not.
Application Architecture
Before getting into testing strategy, it’s important to understand the architecture of a DDD application. I will only present the architecture with a single picture below, but I strongly recommend you to read Uncle Bob’s Clean Architecture blog post in which he explains it really well. I also recommend to read Jeffrey Palermo’s blog post series about the Onion Architecture. It’s those kind of applications I’m talking about in this post.
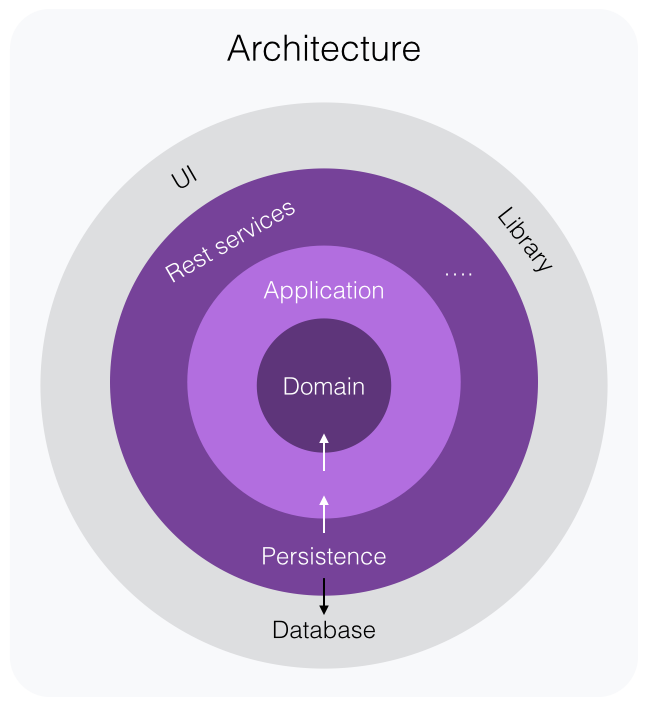
Domain Layer
Domain model in a DDD application should be persistence ignorant. In other words, domain
entities and aggregates doesn’t know anything about the persistence at all. They don’t
have a Save() method or dependencies to repositories. This is great news from the
testing point of view. It means that all the domain logic happens in-memory and there
shouldn’t be any dependencies to outside domain.
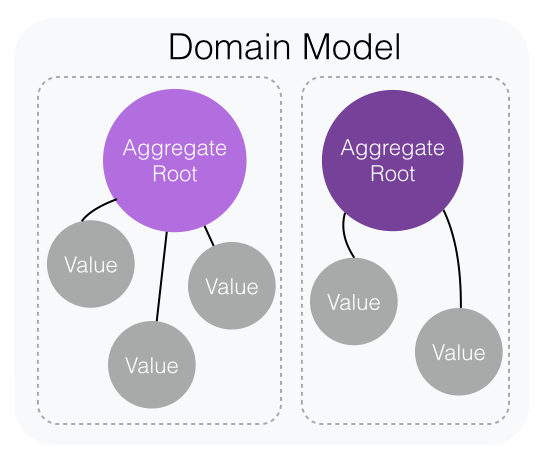
Domain model can be seen as a collection of aggregates which have clear boundaries. To me aggregate is a good candidate for being a unit of testing. Aggregate encapsulates highly cohesive domain concepts together as illustrated in the picture above. Aggregate is persisted as one and parts of it can never be instantiated separately. Rest of the system always operates through the aggregate root and is not aware of the other parts of the aggregate. So, there is a clear public interface to test against.
The only dependencies to mock out are the other aggregate roots of the domain. This is a
case when aggregate takes another aggregate as a parameter to some action. This could be
the case for example when settling payment to an invoice: payment.SettleWith(invoice);`
The tricky part of these tests is arranging the sut (aggregate) into desired state. This problem is unique to domain layer tests, because the aggregates are the state of your application. When testing other layers there is rarely state to worry about.
There are few ways to do aggregate arranging. One can create the aggregate under test using the same factory used in the production code. The downside of this strategy is, that when dealing with a more complex domain it might take several actions against the aggregate, before it’s in the desired state. This makes the test fragile since any failure in those steps would break the test. Personally I don’t see this as a deal breaker, because what you loose is the error pin-pointing benefit of the test, but if you work with small iterations, you will automatically know that the reason of failing tests is the last 5 lines you wrote. The other option is to arrange the aggregate by explicitly setting the internals into desired state. With this style your tests won’t fail if unrelated functionality breaks. However, you might end up having tests that arrange the aggregate into unrealistic states and as a consequence show false positive. Using factory and aggregate’s public interface guarantees that the aggregate state stays valid.
For now, I’m leaning to use factories and executing the needed actions to arrange the state, but this is an area where I’m still actively exploring different solutions.
Persistence Layer
Persistence layer in a DDD application contains implementation of the repositories. Repositories are simple classes that implement data persistence of the domain aggregates. My strategy to test persistence layer is to write test cases against the repositories without mocking out the persistence technology used by repositories. The technology might be a MongoDB or some ORM-tool like NHibernate or Entity Framework. Which it is, doesn’t really matter. The responsibility of a repository is to persist and reconstitute domain aggregates. Database and mapping tool are big part of this and mocking those out would leave little to test.
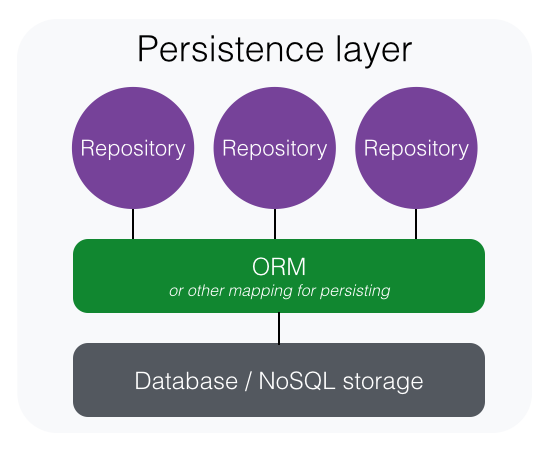
These tests are slower than in-memory unit tests, but that’s ok. They don’t need to be executed as often as unit tests. Only when persistence logic changes occur which usually happens more rarely than domain logic modifications. For more, there’s really no way around it as long as you want to test that the persistence really works.
Repository tests simply store a domain aggregate, query it back and assert that the aggregate stayed intact. This type of testing tests the persistence behavior without depending on details like which technology is in use. So, you are able to switch let’s say from NHibernate to MongoDB without breaking any test case. The same applies if you decided to refactor your database schema. Tests shouldn’t care how the data is persisted, just that it is.
Application layer
Application layer uses domain and persistence layers to implement business functionalities. This layer contains the implementation of the application use-cases. There is usually a class per use-case, but every now and then larger use-cases need to be split into multiple classes. Class that implements a use-case usually starts by getting one or more aggregates from the repository, then performing one or more actions with the aggregate and finally persisting the modified aggregates using the repositories.
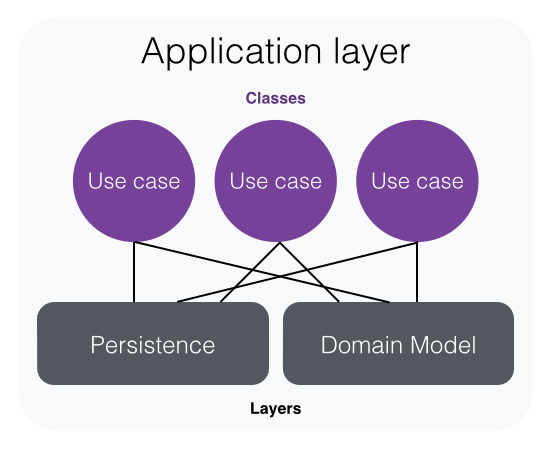
In the application layer a use-case seems meaningful unit to be tested in isolation. By following the Uncle Bob’s rule above, we should mock out all the boundaries that are used. In the case of use-case classes those boundaries are persistence layer (repositories) and domain aggregates which are implemented in the domain layer. Sometimes the application layer might use external services or similar. Those should be mocked out as well.
Testing the features
This is the highest level of automated testing I do at the moment. Feature tests can be written in Gherkin language using for example SpecFlow testing framework. This helps communication with a non-technical persons involved with a project. These tests test complete business processes of the application on the highest level. They make sure that the application as a whole is behaving as expected.
Feature tests should depend only on the application layer. Why not test all the way from the service layer, one might wonder. Service layer is technology dependent and therefore you don’t want to make your tests depend on it. What if you want to change from ServiceStack to WebApi? It would require modifying all the tests although nothing, but external framework actually changes. Service layer is a delivery mechanism. It’s a detail and very very thin layer above the application.
So, make your feature tests depend on application layer and application layer only. Don’t go directly to the persistence layer to assert the application state. When doing arrange part of the test, don’t set application to certain state directly from the persistence layer bypassing the application and domain. In feature tests, always use only the public interface of the application layer. The state changes must be observable through the application layer. Otherwise the change is meaningless. The same applies to setting application in to certain state. If you can’t make the system to certain state through the application actions then that state is not valid state for the application.
Feature tests verify the application behavior as a whole, but on top of that there are two aspects that no other tests verify in my testing strategy. These are: Dependency injection and interception. In feature tests, I initialize the system by using the same composition root that is used in the production. The only exception is that I mock out some very specific parts of the system like e-mail sending. By using the same composition root, I can be sure that all the components are properly configured to the container. Another closely related topic is interceptors. I use interceptors to implement the cross-cutting concerns like logging and auditing. Because feature tests use production composition root, also interceptors are configured and bound in the process. This enables asserting cross-cutting concerns in the feature tests when appropriate.
Bonus
When ever there is a class (or bunch of classes) that deserves to be tested separately in isolation, I write a unit test for it. Most often this is a case when aggregates of the domain model use “helper classes” that do some complex calculations or something else very specific with a lot of business rules.
Conclusion
This testing strategy reflects my current understating on how to get maximum benefit from testing, while enabling refactoring of the system and feeling confident that everything keeps working. My experience is that this strategy also works nicely with TDD approach.
If you follow this testing strategy you’ll get 4 kind of tests:
- Feature tests
- Use-case tests
- Domain aggregate tests
- Repository tests
All these “units” have clear boundaries to write tests against and clear responsibilities to be tested.
I would like to get feedback from the community. Does this strategy make any sense? What are the weaknesses of it?